스트림 파이프라인
Pipeline
- 프로세서로 가는 명령어들의 움직임을 의미
- 연산을 여러개의 stage로 분할해서 처리하기 때문에, 고속화를 위한 하나의 방식으로 볼 수 있다.
Reduction
- 대량의 데이터를 가공하고 축소하는 것. 리덕션의 결과로 데이터 합계, 평균, 카운팅, 최댓값, 최솟값 등을 얻을 수 있다. -> 최종 처리
- 컬렉션의 요소를 리덕션으로 바로 집계할 수 없는 경우, 집계하기 좋도록 매핑, 필터링, 정렬, 그룹핑 등의 중간처리 과정이 필요하다. -> 중간처리
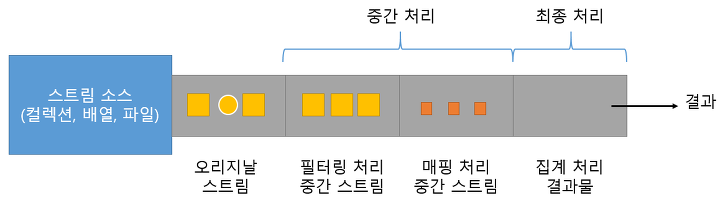
Filtering
요소를 걸러내는 중간처리기능
distinct(): 중복제거filter(Predicate<T> predicate): 조건 필터링. true를 반환하는 요소만 필터링. Predicatepredicate는 조건식
1
2
3
4
5
6
7
list<String> list = Arrays.asList("Dua, Amelia, Birdy, Celine, Dua, Emily");
list.stream() // 스트림 생성
.distinct() // 중복 제거
.forEach(System.out::println);
list.stream()
.filter(n -> n.startWith("B"))
.forEach(System.out::println);
Mapping
요소를 다른 요소로 대체하는 작업의 중간처리기능
map(Function<T, R>): T -> R로 대체됨mapToDouble(ToDoubleFunction<T>): T -> doublemapToInt(ToIntFunction<T>): T -> intmapToLong(ToLongFunction<T>): T -> long
Sorting
요소가 최종 처리되기 전에 중간 단계에서 요소를 정렬하여 최종처리 순서를 변경할 수 있다.
sorted(): 객체를 Comparable 구현방법에 따라 정렬sorted(Comparator<T>): 객체를 주어진 Comparator에 따라 정렬
Comparable 구현
클래스가 Comparable을 구현하지 않으면 sorted()메소드 호출시 ClassCaseException발생
- Comparable 구현한 상태에서 기본 비교 방법으로 정렬하려면 아래 3가지 중 하나 선택해서 sorted()를 호출해야 한다
- sorted()
- sorted((a,b) -> a.compareTo(b))
- sorted(Comparator.naturalOrder())
Looping
요소 전체를 반복하는 것
peek(): 중간처리 메소드이기 때문에, map()처럼 중간 결과물을 만듦.forEach(): 최종 처리 메소드이기 때문에 해당 메소드 사용 후 sum()과 같은 함수를 사용할 수는 없다.
1
2
3
4
5
6
7
8
9
10
11
12
int[] arr = {1, 2, 3, 4, 5};
Arrays.stream(arr)
.filter(a -> a % 2 == 0)
.peek(n -> System.out.println(n))
.sum();
// 6
Arrays.stream(arr)
.filter(a -> a % 2 == 0)
.forEach(n -> System.out.println(n));
// 2, 4
Matching
최종 처리 단계에서 요소들이 특정 조건에 만족하는지를 조사한다.
allMatch(Predicate<T> predicate): 모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하는지 조사한다.anyMatch(Predicate<T> predicate): 최소한 한 개의 요소가 매개값으로 주어진 Predicate의 조건을 만족하는지 조사한다.noneMatch(Predicate<T> predicate): 모든 요소들이 매개값으로 주어진 Predicate의 조건을 만족하지 않는지 조사한다.
Aggregate
집계는 최종 처리 기능 중 하나로, 요소를 처리해서 카운팅, 합계, 평균, 최소, 최대를 계산하여 하나의 값으로 산출하는 작업이다.
대량의 데이터를 하나로 축소시키는 Reduction 연산이라고도 할 수 있다.
count()findFirst(): 첫 번째 요소 반환max(),max(Comparator<T>)min(),min(Comparator<T>)average()sum()
1
2
3
4
5
int min = Arrays.stream(new int[] {1, 2, 3, 4, 5})
.filter(n -> n % 2 == 0)
.min()
.getAsInt();
// 2
커스텀 집계 reduce()
기본 집계 함수들 외에 다양한 집계 결과물을 만들 수 있다.
1
2
3
4
int sum = studentList.stream()
.map(student::getScore)
.reduce((a,b) -> a + b)
.get();
Collect
필터링 또는 매핑된 요소들을 새로운 컬렉션에 수집하고, 해당 컬렉션을 반환해준다.
- T: 요소
- A: 누적기
- R: 요소가 저장된 컬렉션
toList(): T를 List에 저장toSet(): T를 Set에 저장toCollection(Supplier(Collection<T>)): T를 Supplier가 제공한 Collection에 저장toMap(Function<T, K> keyMapper, Function<T,U> valueMapper): T를 K와 U로 매핑해, K를 키로 U를 값으로 Map에 저장 -> 스레드에 안전하지 않다는 단점toConcurrentMap(Function<T, K> keyMapper, Function<T,U> valueMapper): T를 K와 U로 매핑해, K를 키로 U를 값으로 ConcurrentMap에 저장 -> 스레드에 안전해 멀티스레드 환경에서 사용 가능
1
2
3
List<Student> maleList = totalList.stream()
.filter(obj -> obj.getSex() == Student.Sex.MALE)
.collect(Collectors.toList());