최근 속도 개선 이슈 튜너와 상의 후 몇 가지 쿼리의 explain plan을 확인하고 인덱스를 추가할 일이 있었다. 비교적 많은 테이블들을 join해야하는 조회 서비스에서 table full search가 발생하고 있었기 때문이다.
INDEX
오라클의 인덱스 종류는 4가지 이다.
- B-TREE INDEX (가장 일반적)
- BITMAP INDEX
- REVERSE KEY INDEX
- 함수 기반 INDEX
B-TREE INDEX
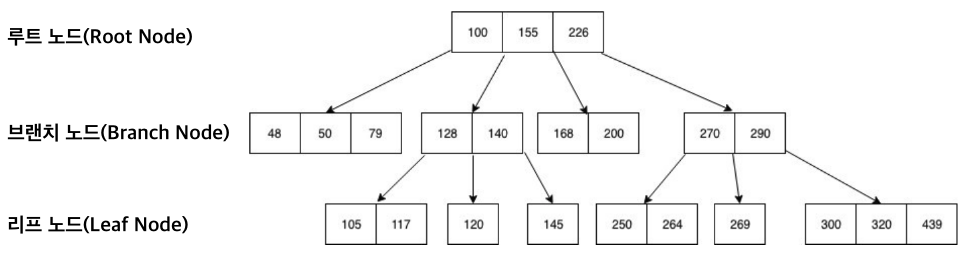
- 나무를 뒤집어 놓은 듯한 모습 - 맨 위쪽 뿌리(Root)에서부터 가지(Branch)를 거쳐 맨 아래 나뭇잎(Leaf)까지 연결되는 구조
- 루트에서 리프 블록까지의 거리를 인덱스 깊이(Height)라고 부른다.
- 인덱스를 반복적으로 탐색할 때 성능에 영향을 미친다.
- 루트와 브랜치 블록은 각 하위 노드들의 데이터 값 범위를 나타내는 키 값과, 그 키 값에 해당하는 블록을 찾는 데 필요한 주소 정보를 가진다.
- 리프 블록은 인덱스 키 값과, 그 키 값에 해당하는 테이블 레코드를 찾아가는 데 필요한 주소 정보(ROIWD)를 가진다. 키 값이 같을 때는 ROWID 순으로 정렬된다
- 리프 블록은 항상 인덱스 키(Key) 값 순으로 정렬돼 있기 때문에 ‘범위 스캔(Range Scan, 검색조건에 해당하는 범위만 읽다가 멈추는 것을 말함)’이 가능하다.
- 정방향(Ascending)과 역방향(Descending) 스캔이 둘 다 가능하도록 양방향 연결 리스트(Double linked list) 구조로 연결돼 있다.
null 값을 처리하는 방식
- Oracle에서 인덱스 구성 칼럼이 모두 null인 레코드는 인덱스에 저장하지 않는다. 반대로 말하면, 인덱스 구성 칼럼 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장한다.
- SQL Server는 인덱스 구성 칼럼이 모두 null인 레코드도 인덱스에 저장한다.
- null 값을 Oracle은 맨 뒤에 저장하고, SQL Server는 맨 앞에 저장한다.
인덱스와 테이블의 관계
- 인덱스와 테이블은 각각의 객체이다.
- 인덱스와 테이블은 논리적/물리적 완전하게 분리되어 있다.
- 리프 블록에는 ROWID(테이블의 최우선 순위 인덱스)를 저장하고 있다.
- 인덱스 스캔이 성공하면 해당 ROWID를 이용하여 테이블액세스를 하게 되는데, 이러한 연산을 테이블 랜덤 액세스(Table Random Access)라 한다.
- 테이블 랜덤 액세스가 많아지면 시스템에 많은 부하를 주게 된다.
- 테이블 랜덤 액세스를 줄이는 것이 인덱스 스캔 튜닝의 핵심 이슈가 된다.
Table Random Access
- 인덱스 스캔 시 인덱스의 리프 블록에는 해당 테이블의 행을 가리키는 ROWID가 존재한다.
- 인덱스 스캔이 완료되면 해당 ROWID를 이용하여 테이블 액세스를 하게 되는데, 이러한 과정을 테이블 랜덤 액세스라 한다.
- 대량의 데이터를 인덱스 스캔 후, 테이블 랜덤 액세스 하는 횟수가 많아지면 시스템에 큰 부하를 주게된다.
- 테이블 랜덤 액세스의 횟수로 인덱스 스캔의 효율을 평가하기도한다.
- 특정 인덱스를 스캔하여 100건이 나왔고, 테이블 랜덤 액세스 후의 결과도 100건 이라면, 인덱스 스캔의 비효율은 없다고 평가한다.
- 인덱스를 스캔하여 100건이 나왔는데 테이블 랜덤 액세스후의 결과는 1건인 경우, 인덱스 스캔의 비효율이 크므로 다른 인덱스를 사용하거나 인덱스 순서 조정 및 인덱스 컬럼을 추가 해야 한다.
- ROWID가 아무리 최우선 순위 인덱스라고 하더라도 각각의 행을 랜덤하게 가져오게 되므로 비용이 매우 크게 발생한다.
ROWID
- 인덱스 스캔 시 인덱스의 리프 블록에는 해당 테이블의 행을 가리키는 ROWID가 존재 (디스크 상의 실제 레코드를 찾아가기 위한 논리적인 주소를 담고 있음)
-
인덱스를 스캔하는 이유는 검색 조건을 만족하는 소량의 데이터를 인덱스에서 빠르게 찾고 거기서 테이블 레코드를 찾아가기 위한 주소값인 ROWID를 얻기 위함.
- ROWID를 사용한 테이블 액세스는 고비용 구조다.
- 읽어야하는 데이터의 갯수가 일정량을 넘는 순간, INDEX RANGE SCAN보다 TABLE FULL SCAN이 빠르다. (항상 테이블 전체를 읽기 때문에 한 테이블에서 몇 건을 조회하든 성능이 일정함)
I/O 메커니즘
- 인덱스 스캔
- 리프 블록
- ROWID
- DBA (디스크 상에서 블록을 찾기 위한 주소 정보)
- 해시함수 (해싱 알고리즘)
- 버퍼헤더 (메모리 상세 주소 = 포인터)
- 버퍼 블록 접근
실행계획
- 실행계획 : 사용자가 SQL을 실행하여 데이터를 추출하려고 할 때 옵티마이저가 수립하는 작업 절차다.
- 옵티마이저는 DBMS의 핵심 엔진으로, 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해준다.
- 컴퓨터 : CPU = DBMS : 옵티마이저
- SQL을 작성하고 실행하면 즉시 실행되는 것이 아니라, 옵티마이저가 여러가지 실행 계획을 세운 뒤, 시스템 통계 정보를 활용하여 각 실행 계획의 예상 비용을 산정하고, 최고의 효율을 가지고 있는 실행계획에 따라 쿼리를 수행하게 된다.
1. EXPLAIN PLAN
- 실행계획을 확인하는 방법에는
EXPLAIN PLAN,AUTOTRACE,SQL TRACE가 있다.
EXPLAIN PLAN -- EXPLANIN PLAN 선언부
SET STATEMENT_ID = 'PLAN1' INTO PLAN_TABLE -- SQL에 PLAN1이라는 ID 부여
FOR
SELECT * FROM REGIONS A --SQL 입력부
LEFT OUTER JOIN COUNTRIES B ON A.REGION_ID = B.REGION_ID;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY -- PLAN_TABLE에 저장된 실행계획 조회
('PLAN_TABLE','PLAN1','ALL'));
- EXPLAIN PLAN의 사용법은 SELECT문 앞에 실행 계획을 저장하라고 명시
- 실행할 SQL에 임의의 ID를 부여한 다음 FOR를 쓰기
- 쿼리문의 실행계획을 PLAN_TABLE에 저장한 후 직접 조회
- 단, EXPLAIN PLAN은 한번에 하나의 쿼리문의 실행계획만을 확인할 수 있고 그 실행계획을 또 확인하기 위해 별도의 SELECT문을 작성해야 한다.
- 데이터를 읽지 않기 때문에 소요시간을 추정한다거나 데이터 관련 I/O정보를 확인할 수 없다.
- 오라클 10g부터는 별도의 PLAN_TABLE을 생성하지 않아도 SYS.PLAN_TABLE$ 테이블을 사용하여 실행 계획을 저장하는 것도 가능해졌다.
- 만약 PLAN_TABLE SYNONYM이 없다면 위 명령어를 통해 오라클에서 제공하는 스크립트를 실행해서 생성할 수 있다.
@$ORACLE_HOME/rdbms/admin/utlxplan
2. AUTOTRACE
SET AUTOTRACE 명령어를 사용하면 위와 같이 자동 추적 사용이라는 문구가 출력되고 쿼리문을 실행시킬 때마다 실행계획을 바로바로 확인할 수 있다.
1
2
3
4
SET AUTOTRACE ON; -- 자동 추적 사용
SELECT * FROM REGIONS A -- 쿼리문 실행
LEFT OUTER JOIN COUNTRIES B ON A.REGION_ID = B.REGION_ID;
- EXPLAIN PLAN 명령과는 달리 한번의 명령으로 여러 개의 SQL에 대한 실행계획을 바로 볼 수 있다.
- AUTOTRACE의 다양한 옵션을 활용하여 데이터를 읽어 들일 수도 있고 데이터를 읽지 않게 할 수도 있으며
- 데이터를 읽게 된다면 I/O정보나 SORT 정보 등의 여러 가지 정보를 추가적으로 확인할 수도 있다.
- AUTOTRACE도 마찬가지로 PLAN_TABLE 테이블이 생성되어 있어야 한다.
- PLUSTRACE라는 롤 받기
$ORACLE_HOME/sqlplus/admin/plustrace.sql
- PLUSTRACE 권한에 GRANT를 활용해 권한 부여
SQL> conn /as system
Connected.
SQL> grant plustrance to hr;
Grant plustrace to hr
3. SQL TRACE
- 실행 계획뿐만이 아니라 여러 세션에서 수행한 SQL의 통계 정보, 수행 시간, 결과 등을 TRAE로 기록하여 이를 파일 형태로 저장하는 방법
- 실행되는 SQL 문의 실행 통계를 세션별로 모아서 Trace 파일을 만들어
.trc확장자로 저장 .trc파일들은 바이너리 형태로 저장되기에 읽기 편한 형태로 파일을 변환하는 과정이 필요한데 TKPROF 유틸리티를 이용하면 쉽게 변환 가능
SQL> conn /as system
Connected.
SQL> grant alter session to hr;
Grant succeeded.
-- session level 실행 방법
SQL> alter session set sql_trace = true;
SQL> execute dbms_system.set_sql_trace_in_session(true);
SQL> execute dbms_system.set_sql_trace_in_session(session_id, serial_id, true);
session altered.
-- session level로 종료 방법
SQL> alter session set sql_trace = false;
session altered.
- TKPROF 사용하여 텍스트 파일로 변환하여 확인하려면
tkprof trace_file.trc new_file.txt sys=no
Scan의 종류
- Scan : 데이터를 읽는 작업. 접근 경로.
- 개발자가 쉽게 유도할 수 있는 방법 : FULL TABLE SCAN, INDEX SCAN
- 테이블에 데이터가 많지 않아 INDEX를 타야하는 시간 소요가 불필요하다고 느낄때, 또는 테이블에서 추출해야 한느 데이터 양이 엄청 많을 때 => FULL TABLE SCAN
- 많은 데이터가 있는 테이블에서 내가 원하는 데이터를 추출해야 하는 상황일 때 => INDEX SCAN
FULL TABLE SCAN
- 테이블 전체 데이터를 읽어 조건에 맞는 데이터를 추출하는 방식
- 테이블 스페이스에 저장된 테이블을 처음부터 끝까지 전체 검색하는 것
오라클은 disk sort와 table full scan을 회피하기 위해서 index를 사용한다. (disk sort : 정렬 작업을 메모리 내에서 완료하지 못할 정도로 용량이 커서 디스크 공간까지 활용한 정렬 연산)
FULL TABLE SCAN을 타는 상황
- 조건절에서 비교한 컬럼에 인덱스가 없는 경우
- 조건절에서 비교한 컬럼에 인덱스는 있지만 조건에 만족하는 데이터가 테이블의 많은 양을 차지하여 FULL TBALE SCAN이 낫다고 옵티마이즈가 판단하는 경우
- 인덱스는 있으나, 테이블의 데이터 자체가 적어 FULL TBALE SCAN이 낫다고 옵티마이즈가 판단하는 경우
- 테이블 생성시 DEGREE 속성 값이 크게 설정되어 있는 경우
- INDEX SCAN이 더 유리한데도 INDEX가 없어서 FULL TABLE SCAN중이라면 INDEX를 하나 만드는 게 좋음
- INDEX를 필요할 때마다 만드는 것은 UPDATE와 DELETE 속도를 저해하기 때문에 고려해보아야 한다.
- 옵티마이저가 판단 후 TABLE FULL SCAN을 탄다면 그냥 두는 것이 좋음
- 인덱스를 이용한 조회에서는 전체 데이터 중에서 몇 건을 조회하느냐에 따라 성능이 크게 달라짐
ROWID SCAN
- ROWID SCAN은 ROWID를 기준으로 데이터를 추출하는 것. 단일 행에 접근하는 방식 중 가장 빠름
ROWID SCAN을 타는 상황
- 조건절에 ROWID를 직접 명시할 경우
- INDEX SCAN을 통해 ROWID를 추출한 후 테이블에 접근할 경우
- ROWID SCAN은 단일 행 접근이 매우 빠르다
INDEX SCAN
- 인덱스를 활용하여 원하는 데이터를 추출하는 방식
인덱스 스캔 힌트 주기
- 사용자가 지정한 테이블과 인덱스를 선택하여 인덱스 스캔을 유도하는 힌트
- 인덱스 스캔을 유도할 테이블과 인덱스를 입력
SELECT /*+ INDEX(테이블 인덱스) */
- 선택도가 높은 컬럼에 대해서 오라클 옵티마이저는 인덱스 스캔보다는 테이블 풀 스캔이 유리하다고 판단한다. INDEX 힌트를 사용하여 인덱스 스캔을 유도할 수 있다
SELECT /*+ INDEX(테이블명 컬럼명) */
- 선택도가 낮은 컬럼을 오라클의 옵티마이저가 인덱스 스캔이 유리하다고 판단하지만 FULL 힌트를 사용하여 테이블 풀 스캔을 유도 할 수 있다.
SELECT /*+ FULL(테이블) */
INDEX SCAN을 타는 상황
- INDEX UNIQUE SCAN : UNIQUE INDEX를 구성하는 모든 컬럼이 조건에 “=”로 명시된 경우
- INDEX RANGE SCAN
- UNIQUE한 결합 인덱스의 선두 컬럼이 WHERE 절에 사용되는 경우
- 일반 인덱스의 컬럼이 WHERE 절에 존재하는 경우
- INDEX RANGE SCAN DESCENDING : INDEX RANGE SCAN을 수행함과 동시에 ORDER BY DESC절을 만족하는 경우
- INDEX SKIP SCAN
- 결합 인덱스의 선행 컬럼이 WHRER절인 경우
- 옵티마이저가 INDEX SKIP SCAN이 FULL TABLE SCAN보다 낫다고 판단하는 경우
- INDEX FULL SCAN
- ORDER BY/GROUP BY의 모든 컬럼이 인덱스 전체 또는 일부로 정의된 경우
- 정렬이 필욯나 명령에서 INDEX ENTRY를 순차적으로 읽는 방식으로 처리된 경우
- INDEX FULL SCAN DESCENDING : INDEX FULL SCAN을 수행함과 동시에 ORDER BY DESC절을 만족하는 경우
- INDEX FAST FULL SCAN : FULL TABLE SCAN을 하지 앟고도 INDEX FAST FULL SCAN으로 원하는 데이터를 추출할 수 있고 추출된 데이터의 정렬이 필요 없으며 결합 인덱스를 구성하는 컬럼 중에 최소 한 개 이상은 NOT NULL인 경우
- INDEX JOIN : 추출하고자 하는 데이터가 조인하는 인덱스에 모두 포함되어 있고 추출하는 데이터의 정렬이 필요없는 경우
reference
[DB] 데이터베이스 옵티마이저(Optimizer)에 대하여
[Oracle] 오라클 실행 계획 확인하기 (EXPLAIN PLAN, SET AUTORACE, SQL TRACE) [DB] 데이터베이스 실행 계획에 대하여 개발자를 위한 SQL튜닝 [SQL 튜닝] 테이블 랜덤 액세스, ROWID, 인덱스 손익분기점 인덱스 기본 원리