도메인 모델이란?
도메인이란, 구현해야 할 소프트웨어의 대상이다.
이를테면 온라인 서점이라는 도메인은 여러 하위 도메인으로 이루어지는데, 주문, 결제, 회원, 배송, 정산, 리뷰 등으로 하위 도메인을 가지고 있다고 볼 수 있다.
도메인 모델이란, 특정 도메인을 개념적으로 표현하는 것이다. 기본적으로 도메인 자체를 이해하기 위한 개념 모델을 의미하며, 개념 모델을 이용해서 바로 코드를 작성할 수 있는 것은 아니기 때문에, 구현 기술에 맞는 구현 모델이 따로 필요하다. 개념모델은 DB, 트랜잭션 처리 등을 고려하고 있지 않기 때문이다.
최근 읽은 도메인 모델의 실제 구현에 관한 아티클 - 트랜잭션은 도메인 모델이 아니다
데이터베이스 트랜잭션, 낙관적 동시성 처리를 위한 버전 정보와 같은 영속성 지식을 도메인 모델에 노출하고 싶지 않을 때, Ioc를 이용해 도메인 모델을 오염시키지 않은 사례에 대해 이야기한다.
💎 도메인 모델 패턴
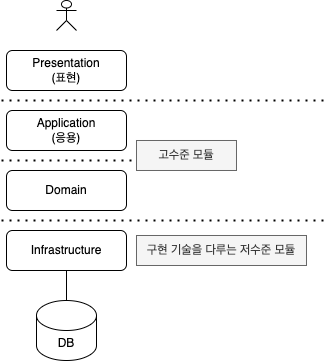
- Presentation: 사용자의 요청 처리하고, 정보를 보여줌
- Application: 사용자가 요청한 기능 실행. 업무 로직을 직접 구현하지 않으며 도메인 계층을 조합하여 기능 실행
- Domain: 시스템이 제공할 도메인 규칙 구현
- Infrastructure: DB, Messaging 시스템과 같은 외부 시스템과의 연동 처리
💎 엔티티와 밸류
엔티티
- 식별자를 가진다. 식별자는 엔티티마다 고유하다. 각 엔티티는 서로 다른 식별자를 갖는다.
- 엔티티의 식별자를 생성하는 방식
- 특정 규칙에 따라 생성
- UUID나 Nano Id같은 고유 식별자 생성기 사용
- UUID란 : 공개 소프트웨어 재단(OSF)에서 만든 고유성이 보장되는 표준 규약
- 구성 : 128bits
Timestamp(8)-Timestamp(4)-Timestamp & Version(4)-Variant & Clock sequence(4)-Node id(12)
- 값을 직접 입력
- 일련번호 사용(시퀀스나 DB의 자동 증가 컬럼 사용)
참고, MySQL에서 UUID를 PK로 사용하려 한다면, 고려해야 될 점이 있다. MySQL은 클러스터드 인덱스로 되어 있어 순차적인 인덱스에 최적화되어 있기 때문에, UUID는 성능적인 측면에서 비효율적이다.
클러스터드 인덱스는 B- 트리 구조로 되어 있어 항상 정렬된 상태를 유지한다.(MySQL8 기준)
시퀀스를 기반으로 순차적으로 값이 올라가는 경우, 데이터를 삽입할 때 구성이 크게 변하지 않지만, 무작위 값을 인덱스로 사용하게 되면 데이터를 추가할 때마다 구조를 재배치해야 하므로 성능에 영향을 미치게 된다.
또한, 인덱스는 하드디스크에 저장이 되는데, 32bytes라는 비교적 큰 값을 사용하게 되면 인덱스 페이지의 크기가 커지는 문제가 있다.
💎 밸류 타입
개념적으로 완전한 하나를 표현할 때 사용한다.
예시)
1
2
3
4
5
6
public class OrderLine {
private Product product;
private int price;
private int quantity;
private int amounts;
}
price 와 amount는 ‘돈’을 의미하는 값이기 때문에, Money타입을 만들어서 사용하면 Money타입을 위한 기능을 추가하여 사용할 수도 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public class Money {
private int value;
// 생성자, getter
public Money add(Money money) {
return new Money(this.value + money.value);
}
public Money multiply(int multiplier) {
return new Money(value * multiplier);
}
}
밸류 타입을 immutable 타입으로 사용하기
- 밸류 객체 데이터 변경시, 기존 데이터 변경 보다는 새로운 밸류 객체 생성하는 편이 보다 안전하다.
- 불변객체는 참조 투명성을 가지고, 스레드에 안전하다.
- 불변 객체가 아니라면, 참조 투명성이 훼손되어 값이 중간에 변경될 가능성이 있다.
엔티티 식별자를 밸류타입으로 만들기
String으로 된 식별자도 밸류 타입으로 만들어서 이를테면 ‘주문번호 OrderNo’ 밸류타입으로 만들어서 명시적으로 사용할 수도 있다.
💎 도메인 모델에 get/set 메소드를 습관적으로 만들지 말자
- set메서드는 도메인의 핵심 개념이나 의도를 코드에서 사라지게 한다. 더 명시적인 메소드 명을 지어, 상태 변경과 관련된 도메인 지식을 코드에 남겨라.
- set메서드를 사용해 도메인 객체를 생성할 경우, 객체가 불완전한 상태로 생성되고 사용될 수 있다. 따라서 생성 시점에 생성자를 통해 필요한 데이터를 모두 받는 것이 좋다.
아키텍처 (표현 - 응용 - 도메인 - 인프라스트럭쳐)
계층구조 아키텍처 구조는, 상위 계층 -> 하위 계층으로의 의존한다. 하위 계층 -> 상위 계층에 의존하지 않는다.
표현, 응용, 도메인 계층이 인프라 계층에 종속될 수 있는데, 이러면 구현 방식을 변경하기 어렵고 테스트하기 어려워진다. -> DIP를 이용해 해결 가능하다
표현 영역
스프링의 MVC 프레임워크가 표현 영역을 위한 기술에 해당한다.
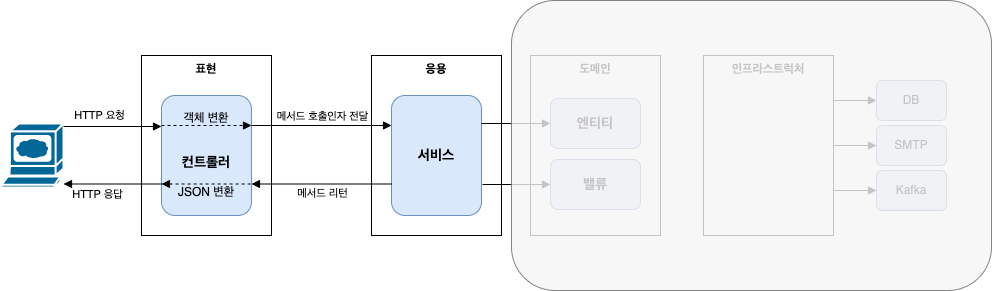
사용자의 요청을 받아 응용 영역에 전달 후, 응용 영역이 처리한 결과를 다시 사용자에게 전달한다.
응용 영역
로직을 직접 수행하기 보다 도메인 모델에 로직 수행을 위임한다.
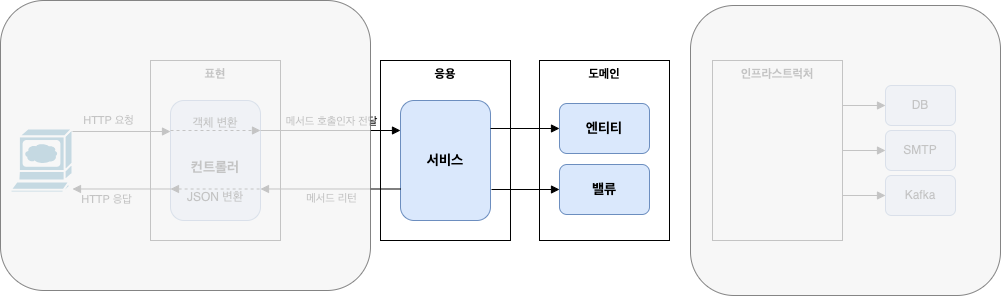
도메인 영역
도메인 모델을 구현한다. 도메인의 핵심 로직을 구현한다.
인프라스트럭쳐 영역
구현 기술에 대한 것(RDBMS연동, 메세지 큐에 메시지 전송/수신, 레디스와 데이터 연동 처리 등)을 다룬다.
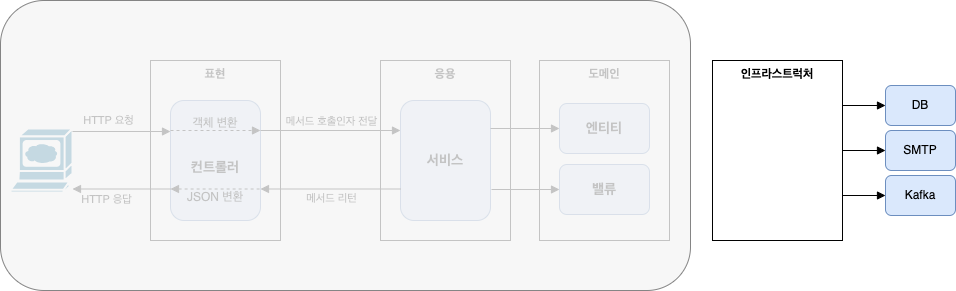
💎 DIP
DIP는 계층구조가 구현 변경과 테스트가 어렵다는 문제를 가진 것을 해결하기 위해, 추상화 인터페이스를 통해 저수준 모델이 고수준 모델에 의존하도록 바꾼다.
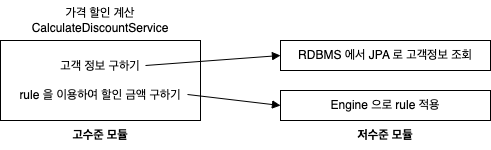
추상화 인터페이스에 의존하도록 DIP를 적용한 구조. 상속은 의존의 다른 형태이다.
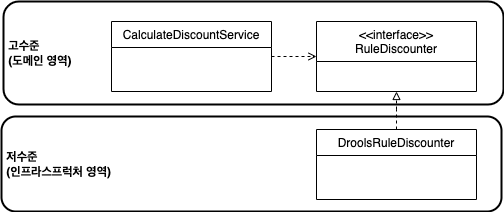
CalculateDiscountService는 구현 기술인 DrollsRuleDiscounter저수준 모듈에 의존하지 않고, ‘룰을 이용한 할인 금액 계산’을 추상화한 RuleDiscounter 인터페이스고수준 모듈에 의존한다.
고수준 모듈은 더 이상 저수준 모듈에 의존하지 않고, 구현을 추상화한 인터페이스에 의존하기 때문에, 의존 주입을 이용해서 저수준 구현 객체를 전달받을 수 있다.
1
2
3
4
5
// 사용할 저수준 객체 생성
RuleDiscounter ruleDiscounter = new DroolsRuleDiscounter();
// 생성자 방식으로 주입
CalculateDiscountService discountService = new CalculateDiscountService(ruleDiscounter);
DIP의 효과
- 사용할 저수준 모듈을 변경해도 고수준 모듈을 수정할 필요가 없다.
- Mock을 사용해 실제 구현 클래스 없이도 서비스 테스트를 할 수 있다.
DIP 적용 주의사항
DIP의 핵심은 고수준 모듈이 저수준 모듈에 의존하지 않도록 하는 것이다.
잘못 적용한 예시
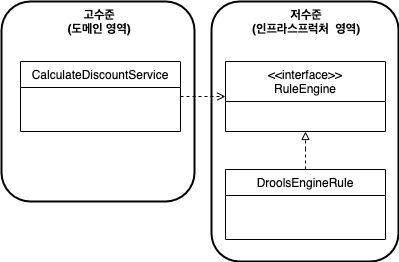
DIP 를 적용할 때 하위 기능을 추상화한 인터페이스는 고수준 모듈 관점에서 도출해야 한다.
CalculateDiscountService 입장에서 할인 금액을 구하기 위해 룰 엔진을 사용하던 다른 엔진을 사용하던지는 중요하지 않고, 오직 규칙에 따라 할인 금액을 계산한다는 것이 중요하다.
DIP 적용시 아키텍처
DIP를 적용하면 인프라스트럭쳐 영역이 응용 영역과 도메인 영역에 의존하는 구조가 된다.
인프라스트럭처에 위치한 클래스가 도메인이나 응용 영역에 정의한 인터페이스를 상속받아 구현하는 구조가 되기 때문에 도메인과 응용 영역에 대한 영향을 주지 않거나, 최소화하면서 구현 기술을 변경하는 것이 가능하다.
DIP를 항상 적용할 필요는 없다. DIP의 이점을 얻는 수준에서 적용 범위를 검토해보고 적용하자.
💎 도메인 영역의 주요 구성요소
- 엔티티
- 밸류
- 애그리거트
- 리포지터리
- 도메인 서비스
엔티티와 밸류
- 도메인 모델의 엔티티: 단순히 데이터를 담고 있는 구조 or DB 관계형 모델의 엔티티가 아닌, 데이터와 함게 기증을 제공하는 객체
- 도메인 관점에서 기능을 구현하고 기능 구현을 캡슐화해서 데이터가 임의로 변경되는 것을 막는다.
- 두 개 이상의 데이터가 개념적으로 하나인 경우 밸류 타입을 이용해서 표현할 수 있다.
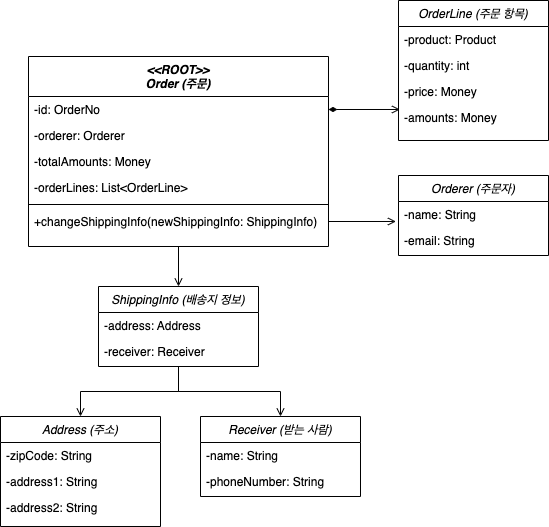
애그리거트
- 도메인 모델이 복잡해지면, 큰 그림을 보기 힘들어진다. 애그리거트는 관련 객체를 하나로 묶은 군집으로, 관련된 객체를 관리하는데 도움이 된다.
- 예시: 도메인(주문, 배송지 정보, 주문자, 주문 목록, 총 결제 금액 등) - 애그리거트 ‘주문’
- 애그리거트는 군집에 속한 객체를 관리하는 루트 엔티티를 갖는다.
- 루트 엔티티: 애그리거트에 속해 있는 엔티티와 벨류 객체를 이용해서 애그리거트가 할 기능을 제공한다.
- 애그리거트를 사용하는 코드는 애그리거트 루트가 제공하는 기능을 실행한다. 애그리거트 루트를 통해서 간접적으로 애그리거트 내의 다른 엔티티나 밸류 객체에 접근하게 된다.
- 애그리거트의 내부 구현을 숨겨서 애그리거트 단위로 구현을 캡슐화 할 수 있도록 돕는 것이다.
리포지터리
- 구현을 위한 도메인 모델 (RDBMS, NoSQL, 로컬 파일과 같은 물리적인 저장소에 도메인 객체를 보관할 수 있도록 하는 것)
- 리포지터리는 애그리거트 단위로 도메인 객체를 저장하고 조회하는 기능을 정의한다.
- 리포지터리를 사용하는 주체가 응용 서비스이기 때문에 리포지터리는 응용 서비스가 필요로 하는 메서드를 제공한다.
- (1) 애그리거트를 저장하는 메서드
- (2) 애그리거트 루트 식별자로 애그리거트를 조회하는 메서드
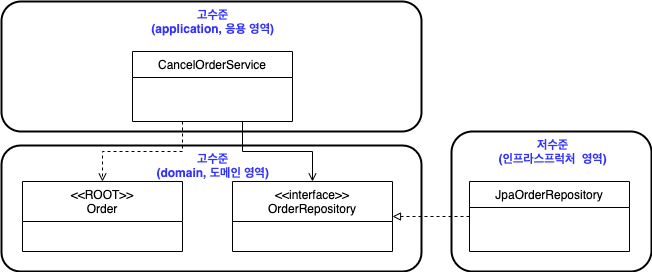
- OrderRepository 는 도메인 객체를 영속화하는데 필요한 기능을 추상화한 것으로 고수준 모듈에 속한다.
- OrderRepository 를 구현한 클래스는 저수준 모듈로 인프라스트럭처 영역에 속한다.
💎 요청 처리 흐름

reference
도메인 주도 개발 시작하기
DDD - 도메인 모델, 도메인 모델 패턴, 도메인 모델 도출 과정, 엔티티와 밸류
[MySQL] UUID의 개념과 성능 개선 결과